This tutorial file is part of the .jar package and can be found in fr.cns.genoscope.nemo.cyclone.application.
Eclipse manages imports automatically, so you do not need to write them manually.
Here you have an extract of Tutorial.java (original location : Cyclone/src/manually-generated/fr/cns/genoscope/nemo/cyclone/application/Tutorial.java )
package fr.cns.genoscope.nemo.cyclone.application;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import javax.xml.bind.JAXBException;
import org.hibernate.LockMode;
import org.hibernate.Query;
import org.hibernate.Session;
import org.hibernate.criterion.Example;
import org.hibernate.criterion.Restrictions;
import fr.cns.genoscope.nemo.cyclone.*
import fr.cns.genoscope.nemo.graphml.db.generated.Graphml;
import fr.cns.genoscope.nemo.hibernate.HibernateUtil;
public class Tutorial {
/**
* This Java class is a sample class to demonstrate how to use Cyclone
* to query and edit BioCyc. In the main function, uncomment lines of
* tutorial you would like to run. Then click on the play button
* at the top of the screen to Run Tutorial.
*
* 1-TutorialEx1: Extract the xml schema as ./Cyclone_Core/schema/Ecoli.xsd .
* 2-TutorialEx2: Extract a Pathway Genome DataBase (PGDB - a Cyc) into a CycloneML file as ./Cyclone_Core/Data/Pgdb/CycloneML/Ecoli.xml .
* 3-TutorialEx3: Load a CycloneML file into the Cyclone database (mySQL).
* 4-TutorialEx4: Query Cyclone using Object Query Language or Criteria API.
* 5-TutorialEx5: Build, export and display graphs.
* 6-TutorialEx6: Edit a PGDB data.
* 7-TutorialEx7: Save data from Cyclone to CycloneML
* 8-TutorialEx8: Save data Cyclone into BioCyc
*/
/**
* Example 1
* Extract the xml schema as ./Cyclone_Core/schema/Ecoli.xsd
* Pathway Tools is required
*/
public static String TutorialEx1(String myOrganism, int max) {
String[] organisms = new String[1];
organisms[0]=myOrganism;
return Biocyc2Xsd.createXsd(organisms,max);
}
/**
* Example 2
* Extract a Pathway Genome DataBase (PGDB - a Cyc) into a CycloneML file as ./Cyclone_Core/Data/Pgdb/CycloneML/
* Pathway Tools is required
*/
public static String TutorialEx2(String myOrganism,int max) {
return Biocyc2Xml.createXml(myOrganism,max);
}
/**
* Example 3
* Load a cycloneML file into the Cyclone database
* mySQL is required
*/
public static void TutorialEx3(String myPath) {
Xml2CycloneDb.importXml(myPath);
}
/**
* Example 4a
* Query Cyclone using Object Query Language or Criteria API
* Find all enzymes for which ATP is an inhibitor with OBJECT QUERY LANGUAGE
* mySQL is required
* This function was inspired by Karp et al. 2004, Application Note in Bioinformatics
*/
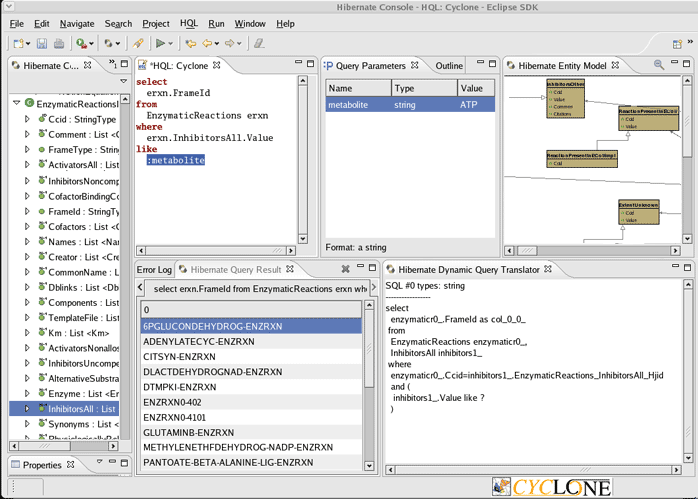
public static List TutorialEx4a(String myOrganism, String metabolite) {
//Open a session
GeneralServices.EasyCycloneOpenOrganism(myOrganism);
//OQL
Query oql = GeneralServices.myEasySession.createQuery(
"select er.FrameId from EnzymaticReactions er "+
"where er.Organism = :orgid "+
" and er.InhibitorsAll.Value like :metabolite");
//Replace variable in oql
oql.setString("orgid",myOrganism);
oql.setString("metabolite","ATP");
//Retrieves results
List myResults =oql.list();
System.out.println(myResults);
GeneralServices.EasyCycloneClose();
return myResults;
}
/**
* Example 4b
* Query Cyclone using Object Query Language or Criteria API
* Find all enzymes for which ATP is an inhibitor with CRITERIA API
* mySQL is required
*/
public static void TutorialEx4b(String myOrganism) {
//Open session
GeneralServices.EasyCycloneOpenOrganism(myOrganism);
try
{
//Create an instance of the enzymatic reaction
ObjectFactory myFactory = new ObjectFactory();
EnzymaticReactions er;
er = myFactory.createEnzymaticReactions();
er.setOrganism("Ecoli");
//Create a criteria
List results = GeneralServices.myEasySession.createCriteria(EnzymaticReactions.class)
.add(Example.create(er))
.createCriteria("InhibitorsAll")
.add(Restrictions.like("Value","ATP"))
.list();
//Display results
//Becareful we extract all the object, so we get an java adress
System.out.println(results);
//Display an attribute of the results
int i=0;
for(EnzymaticReactions myER : results){
System.out.println(myER.getFrameId());
i++;
}
} catch (JAXBException e)
{
e.printStackTrace();
}
//Close the session
GeneralServices.EasyCycloneClose();
}
/**
* Example 5a
* Metabolic Graph : each node represents a metabolite or a reaction
* build the grah, export it in graphml and draw it in a new window
* mySQL is required
*/
public static void TutorialEx5a(String myOrganism, int max) {
String keySession = new String("cyclone");
//Structure to store the tempory graph
ArrayList> myPseudoGraph = new ArrayList>();
//Ask for a DataAccessObject (Dao) to manipulate the generalized-reactions
GeneralizedReactionsDao rdao = new GeneralizedReactionsDao(keySession);
//Get all Reactions
List myRxns = rdao.getAllObjectsByInstance(myOrganism,"|Reactions|");
//List myObNodes = new ArrayList();
// myObNodes.addAll(rdao.getAllObjectsByInstance(orgid,"|Reactions|"));
int i=0;
//For each reaction, extract the left and right metabolites
for(GeneralizedReactions myRxn : myRxns){
System.out.println("Dealing with "+myRxn.getFrameId());
List leftts = rdao.getValueList(myRxn.getLeftt());
for(String metaboliteFrame : leftts){
ArrayList myTmpEdge = new ArrayList();
myTmpEdge.add(metaboliteFrame);
myTmpEdge.add(myRxn.getFrameId());
myPseudoGraph.add(myTmpEdge);
}
List rightts = myRxn.getRightt();
for(Rightt metabolite : rightts){
ArrayList myTmpEdge = new ArrayList();
myTmpEdge.add(myRxn.getFrameId());
myTmpEdge.add(metabolite.getValue());
myPseudoGraph.add(myTmpEdge);
}
if(i==max){break;}else{i++;}
}
//Export it in Graphml format
Graphml myGraph2 = GraphmlServices.buildGraphML(max,"MetabolismNetwork of "+myOrganism,myPseudoGraph);
String filexml2 = GraphmlServices.export2Xml(myGraph2,"Data/Graphs/GraphML/"+myOrganism+"_metabolicnetwork"+(new Date()).getTime()+".xml");
//Display it in a window using jung api
GraphmlServices.displayGraph(filexml2);
}
/**
* Example 5b
* Transcriptional Regulation Interaction Graph: each node represents a gene
* export the graph into Cytoscape format
* mySQL is required
*/
public static void TutorialEx5b(String myOrganism, int max) {
String keySession = new String("cyclone");
Regulation myRegulation = TranscriptionalRegulationCreator.getRegulation( keySession , myOrganism, max);
//print in the console
myRegulation.display();
//Export it in Cytoscape format (SIF, NA)
myRegulation.toCytoscape();
//print it for NeMo clusters analysis tool
//myRegulation.toClusterMatrix();
}
/**
* Example 5c
* Full Graph:
* each node can represent a gene, a reaction or a metabolite,
* each link can represents transcriptional regulation, metabolite regulation, metabolite reaction
* mySQL is required
*/
public static void TutorialEx5c(String myOrganism, int max) {
FullNetwork.completeNetwork(myOrganism, max);
}
/**
* Example 6
* Edit a PGDB
* we correct a reaction stoechiometry of Ecoli_v9.5
* by adding a reactant to the 6PGLUCONDEHYDROG-ENZRXN reaction.
* mySQL is required
*/
public static void TutorialEx6(String myOrganism, String myEnzymaticReactionFrameId, int max) {
//String myEnzymaticReactionFrameId ="6PGLUCONDEHYDROG-ENZRXN";
try
{
GeneralServices.EasyCycloneOpenOrganism(myOrganism);
EnzymaticReactionsDao myERDao = new EnzymaticReactionsDao("cyclone");
EnzymaticReactions myER = (EnzymaticReactions)myERDao.getObjectByFrameandOrganism(myOrganism,myEnzymaticReactionFrameId);
GeneralServices.myEasySession.lock(myER,LockMode.READ);
// get the Generalized Reaction corresponding to the Enzymatic reaction 6PGLUCONDEHYDROG-ENZRXN
String reactionFrameId = ((Reaction)(myER.getReaction().get(0))).getValue();
GeneralizedReactionsDao myRDao = new GeneralizedReactionsDao("cyclone");
GeneralizedReactions myReaction = (GeneralizedReactions)myRDao.getObjectByFrameandOrganism(myOrganism,reactionFrameId);
// build the proton object
ObjectFactory factory = new ObjectFactory();
Rightt protonParticipant = factory.createRightt();
protonParticipant.setValue("PROTON");
protonParticipant.setCoefficient("1");
// Add the proton to the reaction
myReaction.getRightt().add(protonParticipant);
// Save the modified reaction
myRDao.store(myReaction);
// Now we should add the reverse link to be coherent with the BioCyc schema. (this is optional)
// We add the reaction to the list of reactions in which 'proton' appears.
{
// We get the Proton object of the database
ChemicalsDao cDao = new ChemicalsDao("cyclone");
Chemicals proton = (Chemicals)cDao.getObjectByFrameandOrganism(myOrganism,"PROTON");
// We get the AppearsInRightSideOf object
AppearsInRightSideOf myRxn = factory.createAppearsInRightSideOf();
// We add the link and save
myRxn.setValue(reactionFrameId);
proton.getAppearsInRightSideOf().add(myRxn);
cDao.store(proton);
}
GeneralServices.EasyCycloneClose();
} catch (JAXBException e)
{
e.printStackTrace();
}
}
/**
* Example 7
* Extract data from Cyclone to CycloneML
* mySQL is required
*/
public static String TutorialEx7(String myOrganism) {
String keySession = new String("cyclone");
BiocycDao myBiocycDao = new BiocycDao(keySession);
BioCyc myBiocyc = myBiocycDao.getByOrgid(myOrganism);
Session mySession = HibernateUtil.getSessionFactory(keySession).openSession();
mySession.lock(myBiocyc,LockMode.READ);
return ExportCyclone2Xml.exportBiocyc( myBiocyc, "Data/Pgdb/CycloneML/"+myOrganism+".export.xml");
}
/**
* Example 8
* Save an organism with the into BioCyc
* BE CAREFULL it will override your organism. Use this function with caution. You should BACKUP YOUR ORGANISM BEFORE .
* mySQL and pathway tools are required
*/
public static void TutorialEx7(String orgIdCyclone, String orgIdBiocyc) {
String keySession = new String("cyclone");
//int max = 2;
BiocycDao myBiocycDao = new BiocycDao(keySession);
BioCyc myBiocyc = myBiocycDao.getByOrgid(orgIdCyclone);
//If you have a list of orthologs links between Ecoli and your new organism
//OrthologLinks2Cyclone.addOrthologsLinks(myBiocyc,keySession,"Ecoli","Data/Homology/ecocyc.bbh.acineto2.txt",max);
ExportCyclone2Biocyc myExportBiocycJava = new ExportCyclone2Biocyc(keySession,orgIdCyclone, orgIdBiocyc);
myExportBiocycJava.processCyclonePgdb2BiocycPgdb();
}
/**
* Example9
* Add information to your favorite PGDB from a file automatically.
* This example should require investment from yourself. A list of orthologs between your
* organism and Ecoli is required. The file format of the file is:
* EGCCOLIID=YOURORGANISMID
*/
public static void TutorialEx9(String orgIdCyclone, String orgIdBiocyc) {
String keySession = new String("cyclone");
int max = 2;
BiocycDao myBiocycDao = new BiocycDao(keySession);
BioCyc myBiocyc = myBiocycDao.getByOrgid(orgIdCyclone);
// If you have a list of orthologs links between Ecoli and your new
// organism
OrthologLinks2Cyclone.addOrthologsLinks(myBiocyc, keySession, "Ecoli", "Data/Homology/ecocyc.bbh.organisms.txt", max);
}
}
|
|
 Example of Cyclone commands in the terminal
Example of Cyclone commands in the terminal
 Example of Cyclone usage with Eclipse and JBoss
Example of Cyclone usage with Eclipse and JBoss
 -- Debug mode --
-- Debug mode --